


The Inner Workings of The Snowflake Warehouse: A Research-Based Exploration
Understanding Snowflake's Novel Architecture


Snowflake is a single, integrated platform delivered as-a-service. It is extremely elastic and is almost always available. Snowflake possesses capabilities for semi-structure and schema-less data storage, time traveling and end-to-end security. In this blog, we will know about the unique design architecture of Snowflake, its novel multi-cluster,shared-data architecture and why it is a game changer in the modern Data Warehousing world.
First thing first, the Snowflake processing engine has been developed from scratch especially focused to leverage the power of the cloud. The core reason for Snowfalke's new engine was purely to get benefit from the economics, elasticity and service aspects of the cloud, which are not well served by traditional Data Warehouse technologies or Big Data Platforms like Hadoop and Sparks.
In Data Warehousing we have mostly seen the shared-nothing architecture to be very dominant for scalability and use of commodity hardware. But to be honest this architecture tightly couples compute resources and storage resources. So heterogeneous workloads may not be efficiently handled by homogeneous hardware. I mean what is the use of such a setup if we cannot automatically scale the hardware requirements on demands? Also, the nodes are responsible for data shuffling as well as query processing, so if the nodes change due to failures or resizing causing a shuffle of a large amount of the data, there will be a significant performance impact.
The situation is very different in cloud architecture. Platforms like Amazon EC2 have varieties of node types. We can take advantage simply by bringing the data to process in the right kind of node. These platforms handle node failures, scaling of resources with ease with increased availability and provide users with to match their computation resource needs.
How Snowflake Manages all these things?
Snowflake simply Separates the Storage and Compute task. And interestingly, it makes these two vital aspects: storage and computing to be handled by two loosely coupled, and independently scalable services. Compute is provided through Snowflake's shared-nothing engine and the storage is provided through Amazon S3. To reduce the network traffic between compute node and the storage node, each computes layer's clusters cache some table data in the local disk itself. So once the caches are warm (filled), the compute layer performance approaches or even exceeds the pure shared-nothing system. But remember the storage provided by S3 is shared by all multi-clusters in compute layer. This novel architecture is called Multi-Cluster, Shared Data Architecture.
Snowflake's Architecture
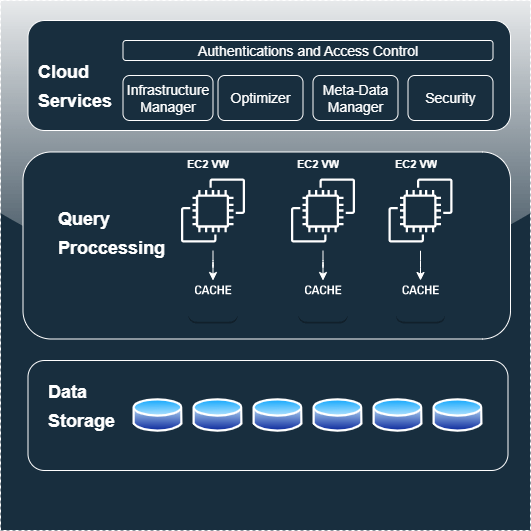
Snowflake's architecture is unique in its approach to scaling and performance, without the need for indexing, tuning, partitioning, and physical storage design considerations. The separation of storage and compute resources is a key aspect of its architecture. Data in Snowflake is stored in Amazon S3 and only incurs storage costs when executing DDL or DML. Virtual Warehouses compute clusters which are nothing but Amazon EC2 instances can be created with various sizes and nodes.
Snowflake's architecture is a service-oriented architecture designed in such a way that it is highly fault-tolerant and independently scalable. These services communicate with each other through RESTful API and fall into three architectural layers.
Data Storage
Snowflake decided to invest time in experimenting with Amazon S3 and found that its usability, high availability and durability were hard to beat with any other infrastructure. So rather than developing their storage services, they spent time on local caching and skewness in compute layer.
Snowflake choose to use Amazon S3 despite its varying performance and restrictions, such as high latency and CPU overhead. However, S3 provides high availability and scalability and is virtually fault-tolerant. Additionally, the S3 API allows Snowflake to read parts of data without loading the entire file, which is a powerful feature.
How does data get stored?
The tables in Snowflake are horizontally partitioned into large immutable files. Multiple partitions are called micro partitions, each containing 50-500 MB of uncompressed data. Within each file, the values of each attribute or column are grouped together and heavily compressed in a well-known scheme called PAX or hybrid columnar architecture. The data gets reorganized in each partition to make it columnar, whereas micro partitions store column values together. Instead of compressing the micro partitions, only the column values are individually compressed.
Here is how row-oriented data is horizontally partitioned and stored in a columnar format in multiple micro-partitions.
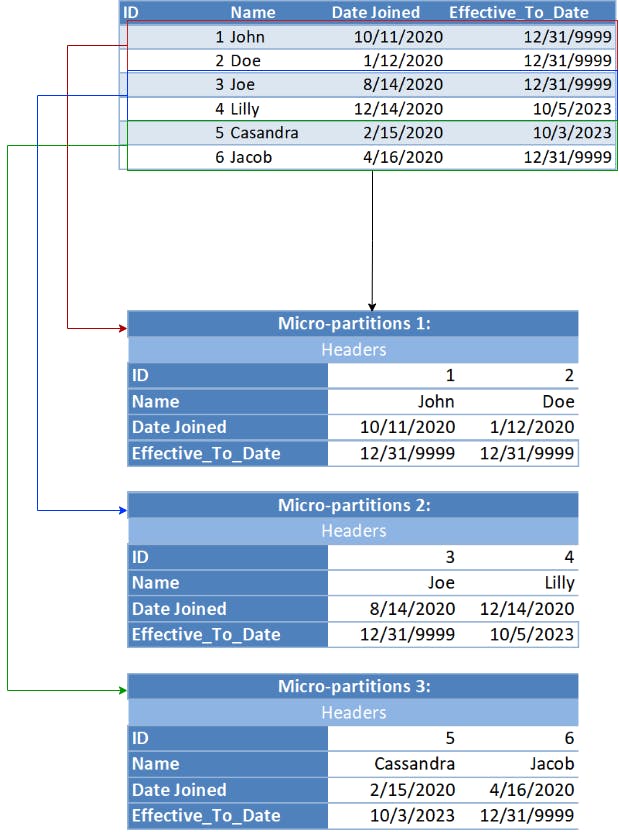
Snowflake stores the metadata and statistics about all the data stored in the micro partitions, so they know the range of values and the number of distinct values for each of the columns in the micro partitions. When a query is executed, Snowflake knows which micro partitions have the data it needs, and targets only those micro partitions where the desired data is stored. Instead of reading the complete file, Snowflake first reads the header and only those columns that are requested, and this is possible because the S3 API allows them to read parts of the file based on the offset and length.
In addition to storing data on S3 for general storage, Snowflake also utilizes S3 to store temporary data that is generated during query operations such as large joins. This includes storing large query results as well. As a result, if the same query is run again in the future, the tables can be retrieved instantly from S3.
Virtual Warehouses
The second layer of the Snowflake architecture is comprised of Virtual Warehouses (VWs). These compute clusters are named after virtual machines that can be created in various sizes and with various numbers of nodes. The individual EC2 instances make up the VW and are also known as the worker nodes.
When a query is submitted each worker node of the respective VW spawns a new worker process which lives only for the duration of the query. The worker node also maintains a cache of data in the local disk. The cache holds the file headers and individual columns of files since they download only the column they needed. The caches live for the duration of the worker node and are shared among concurrent and subsequent workers' processes of its VWs.
Creating or destroying a VM does not incur any costs and has no effect on the state of the database; it is simply metadata. A VW with a single node can be used for low resource-consuming activities, while multiple nodes can be utilized for data loading and complex computations.
Multiple concurrent queries can be executed on the same VW, with the warehouse allocating resources to each query and beginning to run them. If sufficient resources are not available to execute all queries, additional queries will be queued until necessary resources become available. Each user may have multiple VWs running at a given time, and each VW may be concurrently running queries. Every VW will have access to the same shared table without needing to physically copy the data.
VW's elasticity is one of the biggest benefits and differentiators of Snowflake's Architecture. As mentioned in Snowfalke's published paper, data load which takes place 15 hours with 4 nodes might take only 2 hours with 32 nodes within very similar costs yet the user experience is dramatically different.
Cloud Service
This is the most important layer of the system and hence is quoted as the "brain" of the system. This layer is a collection of services that manage the virtual warehouses, queries, transactions and the metadata around database schemas, access control information, encryption keys, and usage activities. Unlike the VWs that are designed for specific user requirements and ephemeral (last for a short time), Cloud Services are heavily multi-tenant meaning a single software instance can hold multiple users. Each service of the layer - access control, query optimizer, transactional manager and others is shared across multiple users. This improves utilization and reduces the administrative overhead as compared to traditional architectures which have a completely private system of incarnations.
The queues executed by the user all pass through the Cloud Service layer. Here early stage of the query life cycle is handled which includes the parsing, object resolutions, access control and plan optimizations. The Cloud Services layer's Snowflake Optimizer leverages metadata to eliminate partitions and decrease the number of micro-partitions that must be retrieved. The metadata is spread out among the nodes in the Virtual Warehouse, which processes the query concurrently on the appropriate subset of data. Cloud service continuously tracks the state of the query and collects the performance counters and detects node failures and is presented to use in GUI.
This layer also handles the concurrency control. The ACID transaction is implied in Snowflake using the Snapshot Isolation (SI) built on top of Multiversion Concurrency Control(MVCC).MVCC is a database optimization technique that creates duplicate snapshots of records so that data can be safely read and updated at the same time. The snapshots are also used in Snowflake for the time-traveling and cloning of database objects. MVCC was also a natural choice as table files are immutable due to the use of S3.
Cloud service also provides the pruning feature to only extract the relevant data through Pruning. Pruning discards the branches that are not worth exploring further and thus narrows search space. Snowflake enables precise pruning of columns in micro-partitions at query run-time. This works excellently for sequential access to large chunks of data like Time-Series. Snowflake keeps pruning the-related metadata data for every individual table file. During query execution, metadata is checked against the query predicates to prune the set of input files. Not all predicate expressions can be used to prune. For example, Snowflake does not prune micro-partitions based on a predicate with a subquery, even if the subquery results in a constant.
Conclusion
In conclusion, Snowflake's multi-layered architecture provides a robust and scalable data management platform. The storage layer efficiently stores data using a unique format, while the compute layer processes queries and transformations and the cloud service manages them all. These layers are isolated from each other, enabling independent scaling for optimal performance. With its advanced architecture and cloud-based infrastructure, Snowflake is a leading solution for modern data warehousing needs.
The above findings and information are based on the paper associated below:
https://event.cwi.nl/lsde/papers/p215-dageville-snowflake.pdf