Fact and Dimension In Data Warehouse
Understanding the Core Concept of Fact and Dimension Table


Fact and Dimension are building blocks of Data Warehouse. Understanding these terminologies is important so that we can model the warehouse correctly. Fact and Dimension work together to give each other real meaning.
Fact
Fact are generally measurement or metrics that describes the business process. Facts provides true meaning to the dimensions. If we quantify that 1000 units of any product is sold. Here 1000 is fact. So fact stores quantitative information that are required for the analysis. Stand alone fact without any dimensions do not provide any meaning to it. Suppose in the previous example if we only specify 1000 instead of 1000 units of particular product what meaning does it provide? Nothing at all. So, fact itself is incomplete but they provide measurement metrics. Due to its quantifiable nature we can aggregate them. It means that we can find sum, min, max, median, mode, average of the facts data as per the requirements.
Dimension
Dimension makes facts complete. They are qualifier of the facts. When we say 1000 units of Shirt, here Shirts are the dimension of product type. Hence dimension provides that lacking meaning to facts and they are the collection of reference information about any facts. We generally see products, time and organizations as dimensions but there can be others as well. We store the dimension along with unique key that identifies data uniquely. But we do not use primary key that directly comes from source. We tend to generate separate primary key to uniquely identify these data.
A general overview on how we load fact and dimension in table.
Depending upon the schema we are using we can normalize or de-normalize the dimension table. In a star schema do not normalize the dimensions. But in snowflake schema we can see that dimensions are normalized and each hierarchy posses uniquely identifying key. Both schemas has pros and cons. If we are using star schema we high data storing cost because as we do not normalize data we can see lot of redundancy in them but we can retrieve them easily. Using snowflake schema means we have to use lots of joins to retrieve data but they are storage efficient. Well its on us what we actually want.
Then the Fact table has the reference of all dimension to identify them along with the facts.
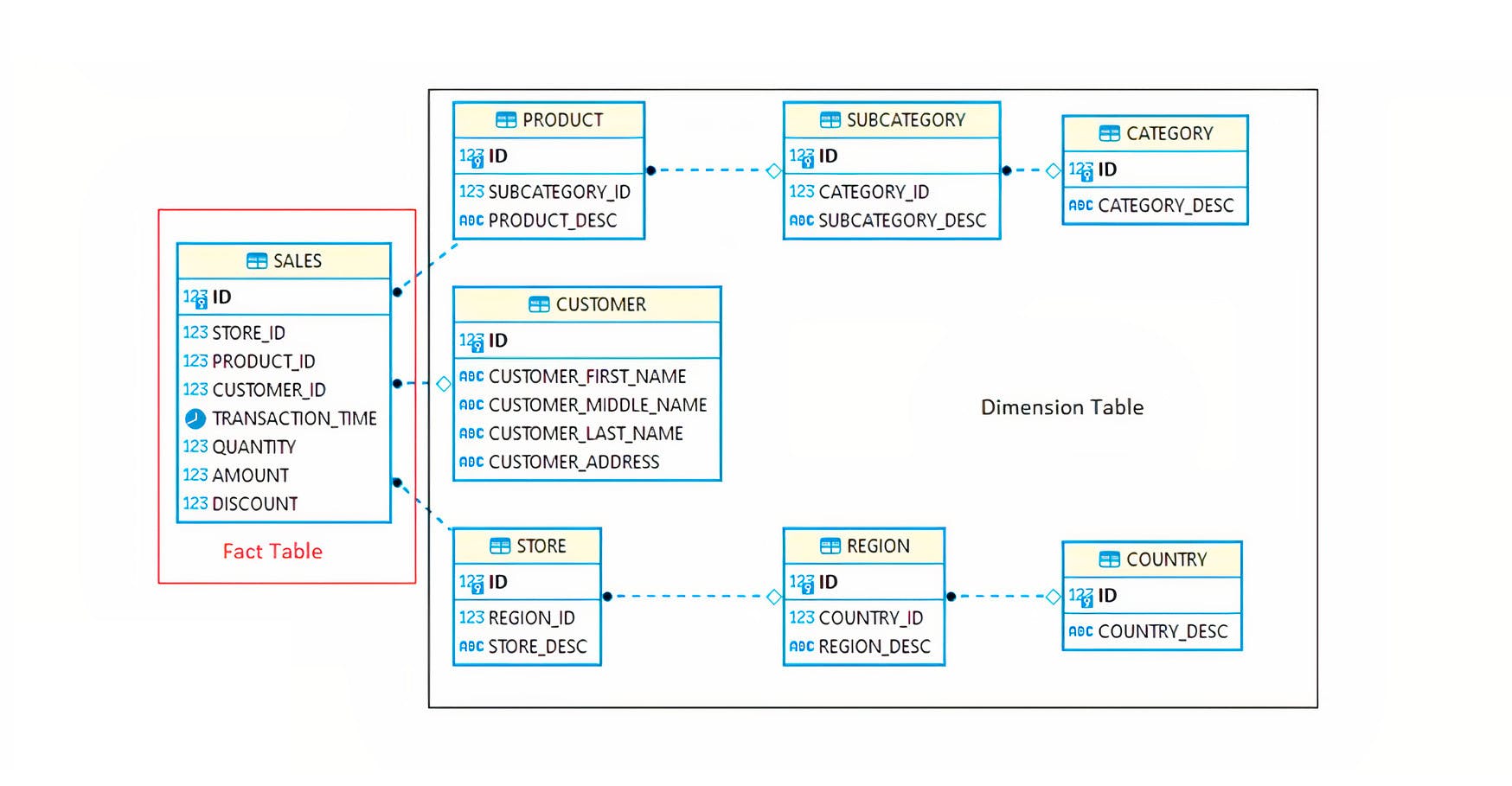
In this figure, you will see a snowflake schema of dimension table as there are separated into hierarchy. Fact table has reference from the dimension tables i.e. the primary key of store, product and customer are foreign key in sales fact table.
So, is there anything you noticed here. If you are a developer which table would you load first? Would it be a dimension table or a fact table?
If you think that you have to load dimension table first. You are absolutely correct. You know that fact table has reference i.e. foreign key from dimension table. If we load fact table before loading dimension table you might miss out on reference of the important newly added dimension or if dimension is removed or updated. That is, if you load fact table first you might not get what you actually want.